Reuters News Agency is considered to be one of the largest multimedia news providers in the world encompassing unparalleled reputation, unmatched coverage in more than 16 languages and an extensive outreach to billions of people worldwide every day. Founded back in 1851, Reuters has still been adhering to its core principles of independence, integrity and freedom from bias.
Reuters - Content Matching
Background
At the same time, our second partner, Microsoft Corporation, being a global leader in the field of computer software and electronics, needs no introduction at this point.

Project overview
Reuters, Microsoft and Contexxt worked together on a recommendation engine that automatically associates content based on relevancy across text, videos, images and slideshows.
CHALLENGE
What were principal drivers that spurred the work on the joint project by Reuters, Microsoft and Context?
In the first place, the key requirement lies in enabling Reuters to deliver more relevant and engaging content to its users. Particularly, Phase 1 of the project aimed at increasing to a significant extent article engagement through automatic association of matching videos to a given text article. Likewise here we focused on demonstrating the feasibility of building a model to match articles to video content.
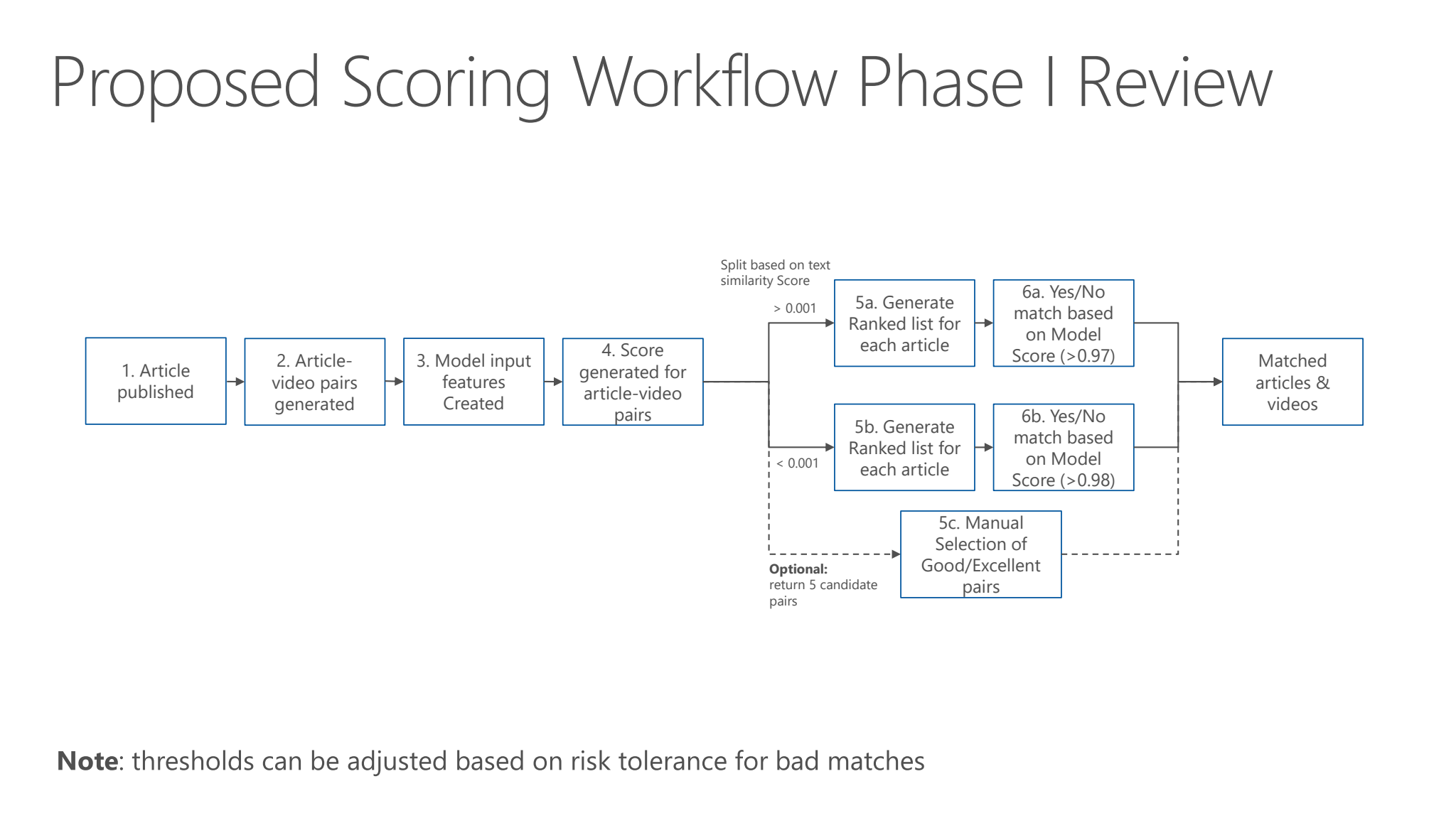
Just as vital, we were requested to implement an integrated system that will enrich the media, correlate data across media channels plus provide rich user experience. The realization of this solution, consequently, contributes to newly emerging insights which supply Thomson Reuters and their clients with advanced opportunities.
Our strategic business goals:
- Improve customer experience by delivering multiple different forms of media content (videos, images, slideshows) in text articles
- Increase revenue generation through more embedded videos
- Automate the content matching process
- Create a process for evaluating content match quality
Solution
The team of professionals from Contexxt spared no effort to achieve maximum results, so our work comprised:
- For articles: comprehensive analysis of article text and any associated metadata (metadata, keywords, topics, slugs etc.)

- For video: creation of video transcripts (intelligently tagged and run through NLP services) along with accurately conducted analysis on the given transcripts
- For images: overall analysis of the image caption and associated metadata (time, place etc.)
- Technologies used: Azure, API, Intelligent Tagging, Meta Data, Machine Learning, JSON, XML, SQL Server, Blob Storage, doc2vec, Logistic Regression, Gradient Boosted Decision Tree, Clustering, Python